Advanced LLM Agents MOOC
- Admin

- Apr 29, 2025
- 5 min read
Updated: May 3, 2025

The "Advanced LLM Agents MOOC (Massively Open Online Course)" offered by the Berkeley Center for Responsible Distributed Intelligence (Berkeley RDI) built on the foundations of their Fall 2024 course on Large Language Models as agents. This advanced course focused on challenges in complex real-world environments like the web and operating systems, explored applications in diverse areas such as web automation, cybersecurity, and theorem proving, and addressed critical aspects of safety and security. The topics are shown by week below. Similar to the first course it was free of charge to MOOC attendees, and included a tiered certification plan, complete with labs and a project.
Another big shout-out and thanks to UC Berkeley Professor Dawn Song and her team for creating another great MOOC. We hope this is a trend for more to come!
You can find more details at: Advanced LLM Agents MOOC
And all of the lectures are on their YouTube channel here: Advanced LLM Agents MOOC Videos
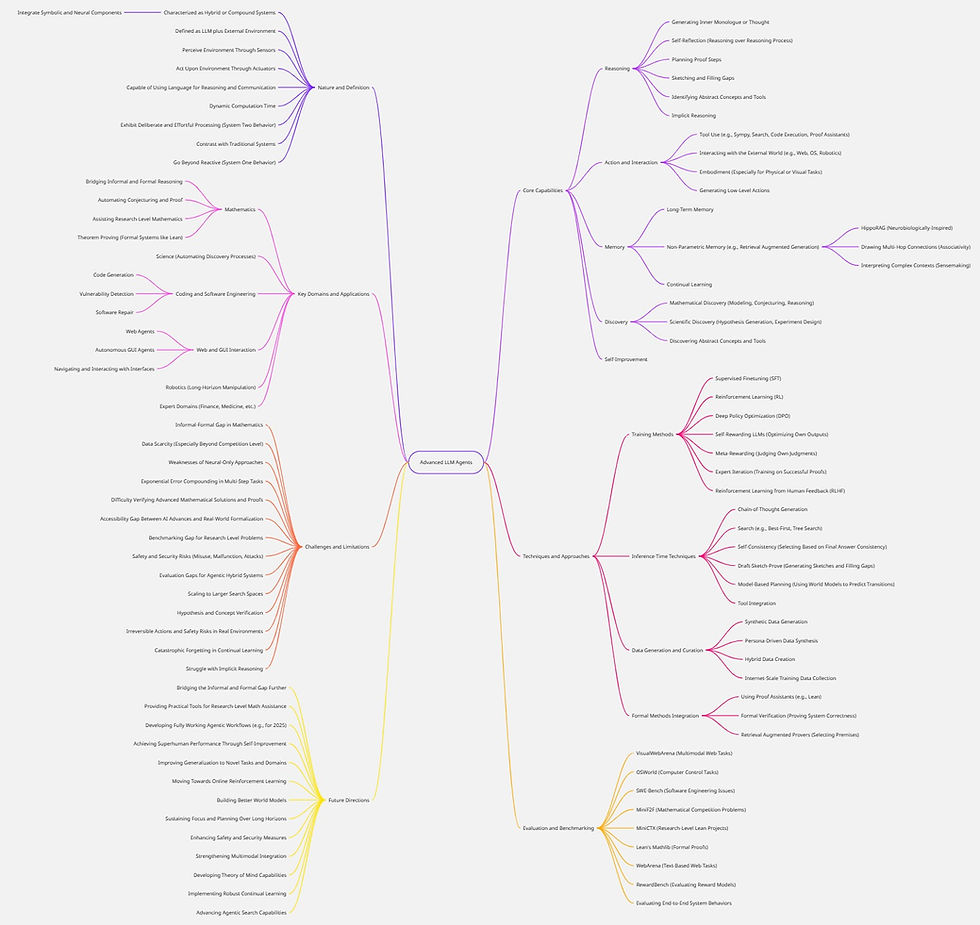
See the very bottom below for our mind map summary of some of the Advanced LLM Agent key concepts.
Week 1
"Inference-Time Techniques for LLM Reasoning” w/ Xinyun Chen (Google DeepMind)
The lecture emphasized strategies for optimizing reasoning tasks using advanced prompting methods, multi-candidate exploration, and iterative self-improvement, all aimed at improving accuracy and adaptability during inference.
Key Points
Standard prompting struggles with reasoning benchmarks, but Chain-of-Thought (CoT) prompting significantly improves performance by modeling intermediate steps.
Zero-shot CoT prompting uses simple instructions like “Let’s think step by step” to elicit reasoning without exemplars.
Analogical prompting enables LLMs to self-generate tailored exemplars and reasoning structures, improving task-specific performance.
Self-consistency boosts accuracy by sampling multiple solutions and selecting the most consistent final answer.
Tree of Thoughts (ToT) allows step-by-step evaluation and iterative exploration, excelling in complex tasks.
Reflexion and Self-Refine techniques empower LLMs to iteratively self-correct and improve their outputs using internal and external feedback.
Self-correction without external feedback (oracle) can worsen reasoning performance, highlighting the need for effective evaluation mechanisms.
Balancing inference budgets and model size is crucial for optimizing multi-sample solutions and computational efficiency.
General-purpose and scalable methods remain essential for designing effective reasoning strategies in LLMs.
Week 2
Lecture with Jason Weston
The lecture focused on improving reasoning and alignment in large language models (LLMs) by enabling them to self-improve through iterative training and self-evaluation.
Key Points
Self-Improving AI: LLMs generate their own training data, evaluate performance, and iteratively refine reasoning capabilities.
System 1 vs. System 2: Effective reasoning requires "System 2" processes like planning, verification, and improvement.
Challenges: Hallucinations, spurious correlations, and sycophancy limit LLM factual reasoning.
Chain-of-Verification (CoVe): Reduces hallucinations through verification steps.
Self-Rewarding & Meta-Rewarding LLMs: LLMs score and improve outputs, meta-rewarding refines judgment mechanisms.
Iterative Reasoning Preference Optimization: Trains models on multiple reasoning paths.
EvalPlanner & Thinking-LLM-as-a-Judge: Enhance evaluation models.
Future Challenges: Focus on system-level reasoning, attention mechanisms, and self-awareness.
Week 3
"Reasoning, Memory, and Planning of Language Agents” w/ Yu Su (Ohio State University)
Explored the evolving role of language agents in AI, focusing on memory, reasoning, and planning.
Key Points
LLM-First vs. Agent-First: Building agents either starting with LLMs or integrating them within broader frameworks.
Inner Monologue & Self-Reflection: Refining reasoning through internal dialogue.
Memory & Long-Term Learning: HippoRAG model enhances memory retrieval.
Implicit vs. Explicit Reasoning: Both are crucial; implicit improves generalization.
World Models & Planning: Adaptive planning strategies for language agents.
Challenges & Future Directions: Memory improvement, reliable self-rewarding, balanced planning, and safe decision-making.
Week 4
"Open Training Recipes for Reasoning and Agents in Language Models” w/ Hanna Hajishirzi (University of Washington)
Focused on open language models (OLMs) and techniques for enhancing model reliability.
Key Points
Open Language Models (OLMs): Promote transparency and reproducibility.
Building and Post-Training: Instruction tuning, preference optimization, and tool use.
Tülu Post-Training Framework: Iterative open-source fine-tuning.
Supervised Fine-Tuning & Data Curation: Importance of high-quality, diverse instruction datasets.
Chain-of-Thought Reasoning: Improves reliability.
Preference Optimization (DPO vs PPO): DPO is more scalable; PPO is computationally heavier.
RLVR: Objective correctness-based reward improves reliability.
Scaling Reasoning at Test-Time: Budget Forcing (BF) and diverse question sets.
Challenges & Future Directions: Refining preference tuning, optimizing verifiable reasoning.
Week 5
"Coding Agents and AI for Vulnerability Detection” w/ Charles Sutton (Google DeepMind)
Explored coding agents in software development and security.
Key Points
Coding Agents: Multi-turn LLMs with dynamic tool use.
Evaluation: Pass@k metric; SWE-Bench.
Design Examples: SWE-Agent and Agentless frameworks.
AI for Computer Security: CTF Competitions and benchmarks like NYU CTF Bench.
Vulnerability Detection: Complementary agent-based approaches.
Big Sleep Project: Mimics security researchers, identifies real vulnerabilities.
Week 6
"Multimodal Autonomous AI Agents” w/ Ruslan Salakhutdinov (Carnegie Mellon University)
Focused on multimodal autonomous agents and their real-world applications.
Key Points
Multimodal Agents: LLMs + VLMs for dynamic web interaction.
VisualWebArena Benchmark: Realistic task evaluations.
Tree Search: Best-first strategy to handle task complexity.
Internet-Scale Synthetic Data: Improve generalization.
Challenges: Search efficiency, irreversible actions, robotic manipulation.
Week 7
"Multimodal Agents – From Perception to Action” w/ Caiming Xiong (Salesforce)
Discussed unified vision-language-action models (VLA-Ms) for complex task performance.
Key Points
Digital Interactions: Multi-app environments.
Scalable Environments: OSWorld benchmark.
Data Synthesis: Agenttrek and TACO frameworks.
Unified Vision Agents: GUI interaction enhancements.
Video Understanding: Efficient processing with xGen-MM-Vid.
Challenges: Balancing reactive actions and planning.
Week 8
"AlphaProof: When Reinforcement Learning Meets Formal Mathematics” w/ Thomas Hubert (Google DeepMind)
Explored AlphaProof's contributions to automated theorem proving.
Key Points
Computer Formalisation: Lean and Mathlib.
Reinforcement Learning Integration: Trial-and-error for proofs.
AlphaProof Architecture: Auto-formalisation, supervised training, RL.
Applications: IMO 2024 participation.
Challenges & Future Directions: Mathlib gaps, combinatorial difficulties.
Week 9
"Language Models for Autoformalization and Theorem Proving” w/ Kaiyu Yang (Meta FAIR)
Focused on large language models and formal mathematical systems.
Key Points
Supervised Finetuning: Math-related corpora.
Reinforcement Learning: Structured verifiable feedback.
Formalisation: Lean integration.
Tactic Generation: Predicting next steps.
LeanDojo & Retrieval-Augmented Provers: Dynamic retrieval.
Managing Proof Search Space: Filtering and pruning.
Autoformalization Challenges: Diagrammatic reasoning.
Future Directions: Generalizing reasoning across domains.
Week 10
"Bridging Informal and Formal Mathematical Reasoning” w/ Sean Welleck (Carnegie Mellon University)
Combines informal human reasoning with formal proofs.
Key Points
Informal vs. Formal Mathematics: Translating intuitive ideas into verifiable proofs.
Lean-STaR: Think-first approach to proof tactics.
Draft-Sketch-Prove: Hybrid proof construction.
LeanHammer: Neural premise selection.
Research-Level Formalization: Tools like miniCTX.
Future Directions: Improving premise selection and reasoning sophistication.
Week 11
"Abstraction and Discovery with Large Language Model Agents” w/ Swarat Chaudhuri (UT Austin)
Demonstrated LLM agents automating mathematical and scientific discovery.
Key Points
LLM Agent Paradigm: Hypothesis and proof space exploration.
Autoformalization: Lean integration.
Neural Theorem Proving: Proof step generation.
Reinforcement Learning (AlphaProof): Refining strategies.
In-Context Learning (Copra): No large datasets needed.
Formal Verification: Applications in compiler correctness.
Symbolic Regression: Discover scientific laws.
Open Challenges: Scaling search and conjecturing.
Week 12
Emerging Challenges in Safe and Secure Agentic AI Systems w/ Dawn Song (Berkeley RDI)
Focused on AI safety vs security, vulnerabilities, and defense mechanisms.
Key Points
AI Safety vs. AI Security: Prevent harm and protect from attacks.
Agentic AI Complexity: Expanded vulnerabilities.
Hybrid System Architecture: Symbolic and neural components.
Security Goals (CIA): Confidentiality, Integrity, Availability.
Workflow Vulnerabilities: At every operational step.
Specific Attacks: SQL Injection, RCE, Prompt Injection.
Evaluation: End-to-end system assessments.
Defense Principles: Defense in depth, least privilege, secure by design.
Defense Mechanisms: Model hardening, input sanitization, policy enforcement.
Web3/Crypto Risks: Protecting sensitive assets.
Mind Map of Concepts Covered